
Statistics: Unlocking the Power of Data Lock
5
Section 3.1
Sampling
Distributions

Statistics: Unlocking the Power of Data Lock
5
The sampling distribution is shown for enrollment in
statistics grad schools. One dot represents:
A. Enrollment at one statistics grad program
B. One sample mean
C. 1000 different enrollments
D. 1000 sample means

Statistics: Unlocking the Power of Data Lock
5
The sampling distribution is shown for enrollment in
statistics grad schools. The population parameter is
closest to:
A. 5 B. 10 C. 20 D. 55 E. 65
The distribution appears to be centered at
about 55.

Statistics: Unlocking the Power of Data Lock
5
The sampling distribution is shown for enrollment in
statistics grad schools. The standard error is closest to:
A. 5 B. 10 C. 20 D. 55 E. 65
The middle 95% of the data appears to
extend about 20 out on either side from the
center.

Statistics: Unlocking the Power of Data Lock
5
Random samples are taken from a population
with mean , and the sample means are shown in
the dotplots below. We estimate that is about
A. 5 B. 10 C. 15 D. 25 E. 200
The distributions appear to be centered at
about 25.

Statistics: Unlocking the Power of Data Lock
5
One set of sample means below was computed
using sample sizes of n = 50 and the other was
computed using sample sizes of n = 200. We have:
A. n = 50 for C1 and n = 200 for C2
B. n = 200 for C1 and n = 50 for C2
C. It is impossible to tell from the information given.
The variability goes down as the sample size
goes up.

Statistics: Unlocking the Power of Data Lock
5
The standard error for the sampling
distribution given in C2 is about:
A. 5 B. 10 C. 15 D. 25 E. 30
The middle 95% of the distribution appears to
extend about 10 on either side of the center.

Statistics: Unlocking the Power of Data Lock
5
The standard error for the sampling
distribution given in C1 is about:
A. 1 B. 2 C. 5 D. 10 E. 25
The middle 95% of the distribution appears to
entend about 2 on either side of the center.

Statistics: Unlocking the Power of Data Lock
5
Samples of size 5 are taken from a large population with
population mean 8, and the sampling distributions for the
sample means are shown. Dataset A (top) and Dataset B
(bottom) were collected using different sampling methods.
Which dataset (A or B) used random sampling?
B, since it is centered at the population
mean of 8.

Statistics: Unlocking the Power of Data Lock
5
Samples of size 5 are taken from a large population with
population mean 8, and the sampling distributions for the
sample means are shown. Dataset A (top) and Dataset B
(bottom) were collected using different sampling methods.
The sampling method for Dataset A is
A. Unbiased
B. Biased high
C. Biased low
The center is
below the
population mean
of 8.

Statistics: Unlocking the Power of Data Lock
5
Standard Error
The more the statistic varies from sample to
sample, the
the standard error.
a) higher
b) lower
The standard error measures
how much the statistic varies
from sample to sample.
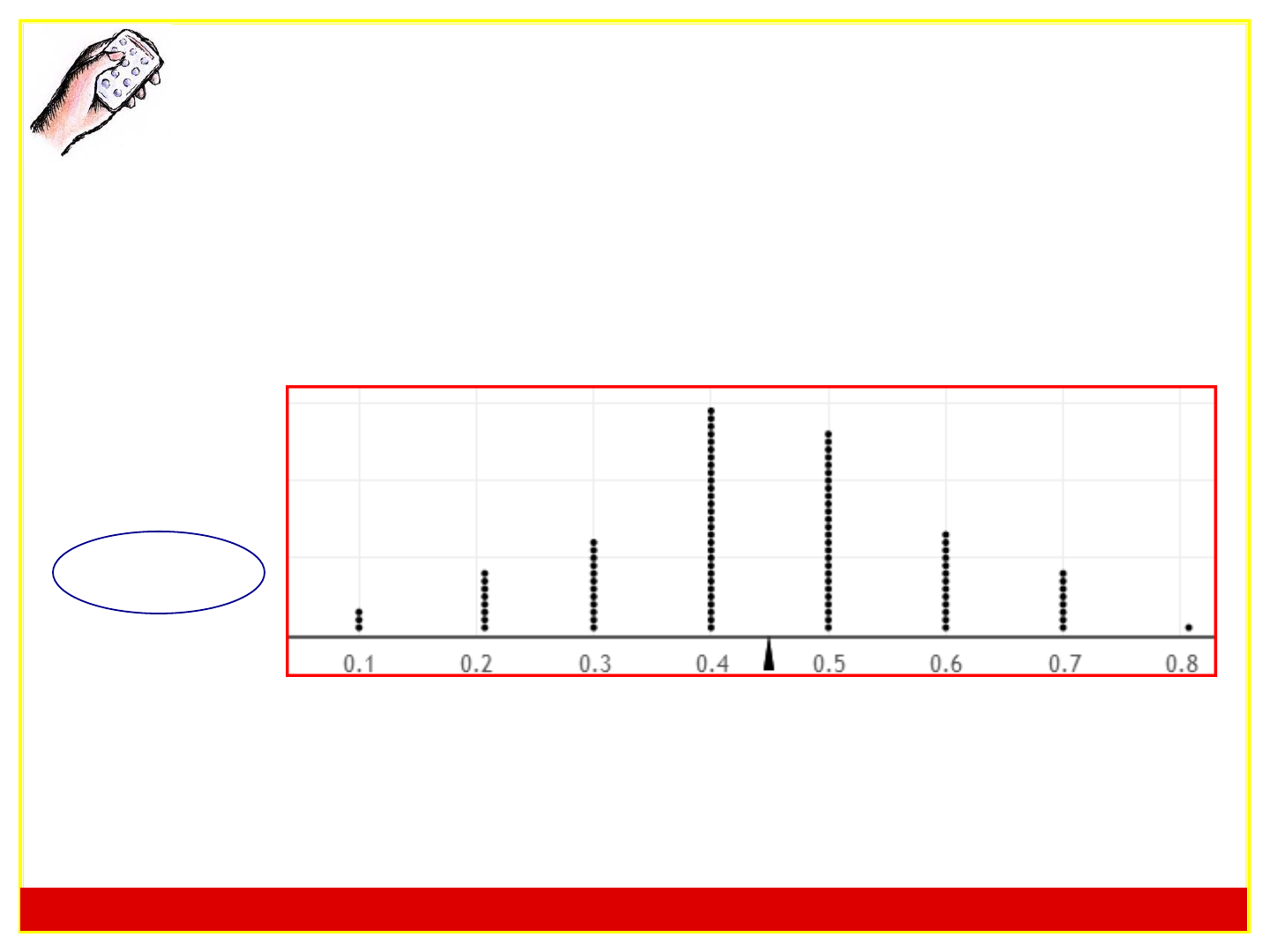
Statistics: Unlocking the Power of Data Lock
5
Reese’s Pieces
The standard error for ො𝑝, the proportion of
orange Reese’s Pieces in a random sample of
10, is closest to
a) 0.05
b) 0.15
c) 0.25
d) 0.35
Middle 95%: 0.2 to 0.7
=> SE 0.5/4 = 0.15
Sampling Distribution:

Statistics: Unlocking the Power of Data Lock
5
Sample Size
Suppose we were to take samples of size 10 and
samples of size 100 from the same population,
and compute the sample means. Which sample
mean would have the higher standard error?
a) The sample means using n = 10
b) The sample means using n = 100
Smaller sample sizes give more variability, so
a higher standard error

Statistics: Unlocking the Power of Data Lock
5
Sample Size
Suppose we were to take a sample of size 10
and a sample of size 100 from the same
population, and compute the sample mean.
Which sample mean would have higher
uncertainty?
a) The sample mean from n = 10
b) The sample mean from n = 100
Higher variability means more uncertainty
